
So, first of all, we have a file with a dictionary - a set of ordered alphabetically words of a any language. (you can easily find and example in google)
In order to quickly navigate through the file looking for the right words, you must convert the original dictionary in special data format, allowing you to quickly perform a search operation on it. In this case, it will be a prefix tree - Trie, which is a set of nodes, which contain appropriate letters (and also a number of child nodes for this node - it is necessary to further reading from the tree).
An example of a prefix tree containing words: [car, card, carry, cart, cat, cel, celery, close, closely, closet, clue]
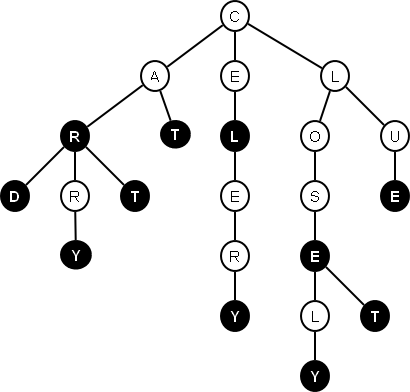
Each terminal node / leaf of the tree (in figure is marked in black) defines the word, which is obtained by passing through the graph to the node, so the task of T9 algorithm is to find leaves of the tree, when path to them passes through all the letters that correspond to the original digital sequence.
To serialize tree it was chosen special node format:

Every (node) consists of 6 bytes:
Once the tree is generated using a special PHP script (https://github.com/nerevar/T9/blob/master/parse_file.php), you can search for words in this tree.
The entire search algorithm is simple - each successive reading of the next node in the tree from a file - letter checked against the letters from the original digital expression and then after it - read child node, or the next node and search continues, until we find all words that match the original digital expression.